- 让人们获取有价值的信息
- 15753173183
- 15753173183
- office@xianpakeji.com
基于混合深度学习的藏医古籍命名实体识别研究

全面对比8个免费开源产品生命周期管理软件
2024年6月13日
开源WebGIS架构
2024年6月28日
基于混合深度学习的藏医古籍命名实体识别研究
作者信息 –
吉林大学商学与管理学院,吉林 长春 130012
刘佳 (1983-),女,博士,副教授,研究方向:知识组织,知识服务
边俊伊 (1997-),女,硕士研究生,研究方向:数字人文、知识管理、知识服务
折叠
Research on Named Entity Identification of Tibetan Medical Ancient Books Based on Hybrid Deep Learning
Author information +
History +
摘要
[目的/意义] 针对藏医古籍知识组织与开发不足的问题,利用混合深度学习方法构建面向藏医古籍的命名实体识别模型,为藏医古籍知识的深度开发与利用提供方法支持。[方法/过程] 根据藏医古籍知识特点,构建ALBERT-BiLSTM-CRF模型。以《四部医典》为数据集,在人工标注与文本预处理的基础上,进行命名实体识别实验,并将实验结果与其他3种常见模型进行对比分析。[结果/结论] ALBERT-BiLSTM-CRF模型对藏医古籍实体识别效果最好,F1-score达到96.28%,与其他方法相比提升约7个百分点。
Abstract
[Purpose/Significance] In view of the lack of organization and utilization of the knowledge of ancient books of Tibetan medicine, a Named Entity Identification model for ancient books of Tibetan medicine was proposed to provide the basis and support for the in-depth mining of knowledge of ancient books of Tibetan medicine. [Method/Process] Based on the data set of the ancient Tibetan medical books”The Four Medical Tantras”, on the basis of manual annotation and text pre-processing, ALBERT-BERT-BILSTM-CRF, BERT-BILSTM-CRF, BILSTM-CRF and BERT were used to carry out named entity recognition experiments, and the experimental results were compared and analyzed. [Results/Conclusion] The F1-score of ALBERT-BERT-BILSTM-CRF model entity recognition reached 96.28%, which is about 7 percentage points higher than other methods.
关键词
混合深度学习 / 命名实体识别 / ALBERT / 双向长短期记忆网络 / 条件随机场 / 藏医古籍 / 知识组织 / 《四部医典》
Key words
hybrid deep learning / named entity identification / ALBERT / BiLSTM / CRF / Tibetan medical text / knowledge organisation / The Four Medical Tantras
引用本文
导出引用
刘佳 , 边俊伊. 基于混合深度学习的藏医古籍命名实体识别研究. 现代情报. 2023, 43(11): 37-46 https://doi.org/10.3969/j.issn.1008-0821.2023.11.003
Jia Liu , Junyi Bian. Research on Named Entity Identification of Tibetan Medical Ancient Books Based on Hybrid Deep Learning. Journal of Modern Information. 2023, 43(11): 37-46 https://doi.org/10.3969/j.issn.1008-0821.2023.11.003
上一篇 下一篇
藏医的研究由来已久,因藏族地区独特的地理人文环境而充满神奇的色彩,藏医与青藏高原文化生活环境密切相关,反映了千百年来藏族人民对自然、健康和生命的认知、探索,以及战胜疾病的智慧与经验成果。藏医不仅在藏族地区广泛流传,更在维吾尔族、蒙古族,甚至在其他的国家和地区都有传播,经过长期的沉淀,已经成为世界传统医学中不可分割的一部分。藏医文献数量巨大,在对少数民族医药文献整理中,55个少数民族的医药古籍一共3 100种,其中藏医就占了2 700种。但由于历史久远,保存条件简陋,藏医古籍文献霉变、腐蚀、虫蛀、损毁、遗失等现象十分严重。2022年4月,中共中央办公厅国务院办公厅印发的《关于推进新时代古籍工作的意见》[1],2022年10月全国古籍整理出版规划领导小组制定的《2021—2035年国家古籍工作规划》[2]等都提出要加强古籍保护与开发利用。对藏医古籍知识的保护与传承,深度开发与利用,对藏医的文化教育、科学研究、临床实践、药物开发,对维护国家文化主权与安全,弘扬中华优秀传统文化,铸牢中华民族共同体意识,具有重要意义。
本文以藏医古籍文献为对象进行命名实体识别(Named Entity Identification,NER)研究,利用深度学习技术识别、提取藏医古籍中具有特定意义的实体,如疾病、症状、病因等,为藏医古籍知识的深度挖掘与利用提供基础与支持。
1 研究现状
1.1 传统的藏医文献研究方法
传统藏医文献研究主要采用统计分析、可视化分析和知识组织等方法。在基于统计规则的方法中,才让南加等[4]对《四部医典》中治疗“痞瘤”方剂配伍规律进行研究,利用统计和关联规则的方法,抽取出相关的高频次的药物与方剂,以总结治疗规律,这种方法对藏医药规律研究具有重要意义,但传统的统计方法无法挖掘出潜在的、丰富的藏医古籍文献知识。文成当智等[5]以藏医“味性化味”理论对《四部医典》的用药规律进行可视化的分析,详细从“味性化味”理论视角,应用Gephi v0.8.2可视化软件等方法梳理3 000余函藏医古籍文献,作者从藏医更核心的理论对藏医古籍内容、规律进行梳理与分析,但限于目前藏医古籍文献的数字化开发程度,所涉猎的古籍文献量仍局限于一部古籍。娘本先[6]研究了藏医古籍本草知识的描述方法,并利用其所构建的知识元和知识体模型,构建藏医古籍本草知识库,实现基于规则库的知识检索功能。上述研究中,对藏医知识内容的研究多采取人工抽词与统计的方式,准确性高,但是无法为大规模的藏医知识抽取与开发利用提供支持。
1.2 基于机器学习的传统医学文献命名实体识别方法
相较于传统的藏医文献研究方法,基于机器学习的自然语言处理技术应用于传统医学文献研究,为藏医知识提取、检索、问答系统构建以及元数据标注等提供了重要的参考。目前,命名实体识别方法在传统医学文献的应用多集中在对传统医学文献中的疾病、药物的抽取上。罗计根等[7]提出,一种融合梯度提升树的双向长短期记忆网络的关系识别算法(BiLSTM-GBDT),开始了机器学习方法在识别中医文本实体领域的尝试。Tao Q等[8]通过构建BERT-CNN-LSTM的文本建模框架,从上下文中学习字符的表示,来进行中医药说明书的文本实体识别。Chen T等[9]利用生物创造与化学疾病关系语料库、中医文献语料库和i2b2 2012时间关系挑战语料库,进行关系提取的预训练模型BERT微调训练。肖瑞等[10]采用BiLSTM-CRF模型对中医文本中的疾病、草药、症状3类实体进行实体抽取,获得较高的测试结果。谢靖等[11]对古代中医繁体文献进行增强的SikuBERT预训练模型研究,有效提高了中医命名实体识别的效率。何家欢等[12]通过中国知网获取藏药药理相关文献155篇,构建中文藏医药药理实体识别语料库,设计基于BiLSTM-CRF深度学习模型的藏药药理命名实体识别方法,采用信息抽取技术从科技文献中提取并识别藏药药理,为藏医药文献研究提供新途径。
上述研究为藏医古籍的实体识别研究提供了方法与思路的借鉴。目前基于机器学习的藏医古籍文献研究成果仍较为匮乏。作为世界四大传统医学之一,藏医学有其独特的诊疗与用药方案,完全复用中医文献的研究方法不能够准确地反映藏医学的知识特点,也不能精准地识别藏医文献中的实体与关系。
综上,针对藏医古籍文献的内容分析仍以统计分析与共现分析方法为主。藏医文献体例的独特性导致藏医知识及其关系呈现分散、不明确等特点,无法直接复用传统医学文献的方法进行实体识别。目前收录藏医资源的开放数据库较少,尚未建立专门的藏医语料库,使得利用深度学习模型进行藏医知识提取与深度分析研究方面的进展缓慢。而藏医古籍文献作为藏族文化与智慧的载体,包含丰富的传统医学知识,具有重要的挖掘价值,因此,基于藏医古籍文献的实体识别还有待更深入的研究。基于此,本文以小样本的藏医古籍文献资源为研究对象,将人工标注与深度学习方法相结合,尝试构建ALBERT-BiLSTM-CRF模型对藏医古籍《四部医典》中的疾病、症状、药物、方剂等进行实体识别实验,并与BERT-BiLSTM-CRF、BiLSTM-CRF、BERT 3种目前普遍使用的实体识别模型进行比较分析,以确定藏医古籍文献实体识别的最优模型,解决传统命名实体识别方法准确率低的问题。
2 关键技术与藏医古籍命名实体识别模型构建
本文利用Albert、BiLSTM、CRF模型等深度学习模型与自然语言处理技术构建藏医古籍命名实体识别模型,旨在为藏医领域知识图谱的构建、知识检索、知识推理等提供基础与方法支持。
2.1 关键技术
2.1.1 ALBERT模型
ALBERT (A Lite BERT)[19]是BERT的改进版本,它拥有3个方面的创新。
首先是参数共享,降低Transformer Block的整体参数量级。BERT的Transformer编码器是一个包含了Encoder-Decoder结构的编码器,同时使用了多头自注意力层以便处理更长的序列信息[20],而ALBERT模型只保留了Encoder的部分,降低了原来BERT的多层Block的迭代,使参数降低,从而实现参数共享。
其次是词向量分解,有效降低词向量层参数量级。BERT中的隐藏层(H)和编码层(E)是相等的,如果词表的大小是V,当V很大时,E参数变大,即V*H=V*E。在ALBERT中通过降低E的纬度进行因式分解,当H≥E时,即V*E+E*H,降低了模型的参数,提高了模型的性能。
最后是使用句子顺序预测的自监督损失(Sentence-Order Prediction,SOP)方法,可以增强文中句子的上下文联系。在BERT中使用的是下句话预测(Next Sentence Predict,NSP),NSP主题预测任务会使在学习中出现知识重叠的现象。而SOP避免了主题预测,使句子之间更具有连贯性,提高了ALBERT下游多语句编码任务的性能。
2.1.2 BiLSTM模型
BiLSTM (Bidirectional LSTM)双向长短期记忆网络模型是由循环神经网络模型LSTM改进得到的一种新模型。LSTM (Long Short-Term Memory)是长短期记忆网络,在RNN (Recurrent Neural Network,RNN)循环神经网络的基础上增加了3个门结构,分别为输入门、遗忘门和输出门。分别控制变量的输入、输出和细胞单元的状态[21]。门结构可以解决对于较长输入的反向传播过程中RNN出现梯度消失和梯度爆炸的问题。BiLSTM是双向的LSTM模型,向前可以获得输入序列的上文信息,向后可以获得输入序列的下文信息。在Forward层从1时刻到t时刻正向计算一遍,获得并保存每一个时刻向前隐含层的输出。在Backward层沿着时刻t到时刻1反向计算一遍,获得并保存每一个时刻向后隐含层的输出[22]。最后在每一个时刻结合Forward层和Backward层的相应时刻输出的结果获得最终的输出。
2.1.3 CRF模型
CRF (Conditional Random Field)条件随机场模型近年来被广泛应用于序列标注问题中,在多个研究领域都取得了良好的效果。条件随机场模型综合了隐马尔可夫模型和最大熵模型的优点,同时克服了隐马尔可夫模型严格的独立性假设,并解决了最大熵马尔可夫模型和其他非生成的有向图模型所固有的标记偏置的缺点[17]。CRF中,通过正则化的极大似然估计或者极大似然估计对训练集进行训练学习,得到条件概率模型,来解决命名实体识别中的序列标注问题。将观测序列记为X,标记序列记为Y,则线性链条件随机场P(Y|X) 的预测序列为Y=(y1, y2, y3, …, yn),取值为y的条件概率的简化表现形式为𝑃(𝑦∣𝑥)=1𝑍(𝑥)exp∑𝑘=1𝑘𝑤𝑘𝑓𝑘(𝑦,𝑥),Z(x) 为归一化因子;exp为指数函数;wk代表特征函数fk(y, x) 对应的权重;K代表定义的特征函数个数。通过构建该条件概率分布,CRF能够生成观测序列对应的标注序列,从而胜任词性标注、实体识别等一系列以标注为核心的自然语言处理任务。
2.2 藏医古籍命名实体识别模型构建
针对藏医古籍文献样本量小、内容多样,且语义复杂等特点,本文的命名实体识别算法以预训练模型ALBERT为基础,构建ALBERT-BiLSTM-CRF模型进行藏医古籍文本的命名实体识别研究。
本文所使用的实体识别模型共有3层,如图 1
所示,第一层是ALBERT层,先将输入文本进行句子标记,句首标注[CLS],句尾标注[SEP],句子的上层抽象信息作为最终的最高隐层输Softmax中,通过词向量分解降低参数量级。ALBERT将每一层Transformer Encoder Block参数共享,之后学习的每一层,通过重用第一层并进行共享,使每一层都学习到了第一层的信息,相当于只学习了一层。最后将文本转化为字向量X1、X2、X3…与BiLSTM层相连接。

| 图 1 ALBERT-BiLSTM-CRF模型 |
第二层是BiLSTM层,通过学习正向的h (h1、h2、h3…)信息和反向的h (h1、h2、h3…),提取出上下文本特征,计算最大概率值,输出Y (Y1、Y2、Y3…)。
第三层是CRF层,准确对BiLSTM输出内容进行解码,做实体类型的序列标注,为每个字符输出最可能的实体标签。
3 实验与结果分析
模型实验之初,需要确定数据来源并进行数据预处理,构建实验数据集;然后针对藏医古籍知识特点,设计、训练、优化实体识别模型。
3.1 数据来源
藏医古籍文献种类繁多、复杂,多为半结构化的信息文本。目前中医领域已经建立了不同规模的中医语料库,极大地推动了人工智能技术在中医文献知识挖掘、知识关联与深度开发中的应用。然而,藏医古籍中记载的藏药、疾病名称等有其独特的命名规则与记录方式,其语料在语法与内容编写方面,与中医语料存在较大的差异,因此需要对藏医文献预先进行精确标注,构建以藏医语料为基础的数据集,为后续智能化处理提供数据基础。
《四部医典》是一部藏医理论与实践相结合的经典著作,也是藏医学的奠基之作,内容广泛,涉及藏医理论知识、临床经验、药物功能、治疗方法等。藏医学的诊疗方法主要以《四部医典》为依据,是藏医研究中不可或缺的文献,因此,本文选择1987年出版的,由宇妥· 元丹贡布等著、马世林等译注的《四部医典》[13]为主要语料来源,辅之参考相关研究论文与参考资料,构建藏医古籍实体识别实验的数据集,以确保所构建的命名实体识别模型具有普适性与推广性。
3.2 实体类型
在确定数据来源的基础上,根据数据集特点来定义实体类型。命名实体识别的概念目前还没有统一的定义,Marrero等总结了前人对命名实体的定义,通过分析和举例等方式,最终得出应用方面的需求目的是定义命名实体唯一可行的标准[14]。本文以此为依据,通过分析《四部医典》的内容,并参考相关传统医学命名实体研究,确定藏医古籍的实体类型。
《四部医典》中记载了许多临床治疗方法,除药物治疗外,还包括药浴治疗法、催吐疗法、放血疗法、灌肠法、鼻药疗法等特色疗法。在药物性能方面,《四部医典》记载了汤剂、丸剂、散剂、膏剂等3 000余种方剂,对草药的功效、属性、气味等都有详细的记载。在专家的指导下,根据文献内容特点,本文制定了命名实体识别模型中的实体类型及其标识,将具有藏医特色的实体类型归纳为6类,疾病、病因、症状、药物、方剂、疗法,如表 1
所示。
| 表 1 《四部医典》实体类型 |
| 序号 | 标签 | 实体类型 | 解释 | 举例 |
| 1 | DIS | 疾病 | 藏医学认为“隆、赤巴、培根”是维持人体正常生命活动的基本物质基础,当三因素失去平衡状态时,人体就会产生疾病[15] | ①【不安龙症六十又三】龙病有63种 ②【最后未熟热与毒症病,最初命名木布培根症】后者未能最后成型,成为热毒症,这就是木布培根病 |
| 2 | PAT | 病因 | 藏医中指不适饮食、不当行为、反常季节和发病机理等推导出来的疾病发生原因 | 【病因培根饮食沉且凉,病缘所依不惯又不适】培根性重而凉,它由所依①、不习惯、不合适、本质是不消化4种外因 |
| 3 | SYM | 症状 | 是指人在发生疾病时所表现出的各种异常的状态 | 【胆虚失眠口驰目舌黄,痰虚大汗睡眠多梦呓】胆虚②症状是失眠,口用不严,眼睛与舌苔都呈现出黄色;痰虚③症状为大汗,睡眠时昏眩多梦 |
| 4 | RES | 药物 | 药物是用以预防、治疗及诊断疾病的物质 | ①【赭石长石炉甘寒水石,硼砂麝香为丸黑痞息】赭石、长石、炉甘石、寒水石、硼砂、麝香制成丸剂治疗黑痞症 ②【(羊癫疯)饮食禁忌陈酥酒肉血,可进蜂蜜新乳酪甘】羊癫疯饮食需要禁忌饮酒,不能吃陈酥油、血肉等;可以吃血蜂蜜,鲜酥油、酪浆等素食 |
| 5 | DRU | 方剂 | 是根据配伍原则,总结临床经验,以若干药物配合组成的药方 | 【蒺藜药酒蒺藜青稞曲,蒺藜水煎取汁浇灌之,骨节肾风黄水得解除】蒺藜、青稞、酒粬,混合发酵的醪糟取水制成的蒺藜药酒,可以治疗关节、肾风并、黄水症 |
| 6 | THE | 疗法 | 藏医特色治疗疾病的方法,如刺针放血、针灸疗法、藏医按摩、敷浴疗法等 | 【可施火灸疗法之病症,食积火衰浮肿水肿痞】灸法适应症有消化不良、胃火衰败、浮肿、水肿、痞块等 |
| 注:①所依:寒性龙病成分多的人;②胆虚:赤巴虚热症;③痰虚:培根虚热症。 |
3.3 数据标注
数据标注是使未经处理的文本能够被机器识别和学习的信息处理过程,通常包括自动标注和人工标注两种方式。自动标注是利用机器和算法对文本内容进行识别的方式;人工标注是标注人员利用标注工具对文本内容进行标识的方式。人工标注与自动标注相比具有高效、准确的优势,但是在标注效率上要远远低于自动标注方式。鉴于上文所述藏医古籍体例的独特性,本文采用人工标注方式进行数据标注。
按照上文所制定的实体类型,对《四部医典》进行人工标注。《四部医典》共4部,分别是《总则本》《论述本》《密诀本》和《后序本》,包括基础理论、生理解剖、疾病诊断治疗的原则和方法、预防、药物等内容。本文主要对《四部医典》三、四部中约3万字内容进行了人工标注,得到4 350条数据,并邀请具有藏医背景的专业人员对数据集进行多轮的检验与修正,构建出藏医词表。具体标注示例如表 2
所示。
| 表 2 人工标注示例 |
| 原文 | 实体 | 实体类型 |
| 主药加勾藤、藏贯众、川乌配伍。主治一切毒症 | 勾藤 | 药物 |
| 藏贯众 | 药物 | |
| 川乌 | 药物 | |
| 毒症 | 疾病 |
本文采用BIO标注法进行随机标注,其中“B”表示实体的首部(Begin),“I”表示实体的中间(Inside),“O”则表示该元素不属于任何实体类型(Outside)。在对文本数据进行分句的基础上,对分句后的结果按照标注规则对语料库中的疾病和药物等进行序列标注。对语料中词语的标注采用B/I-XXX的形式,B/I表示此词是实体的内容,XXX表示实体的类型。O表示该词不是实体中的内容。使用Label Studio平台标注《四部医典》三、四部,得到24 918个实体,其中,疾病类实体14 049个,病因类实体506个,症状类实体209个,药物类实体8 919个,方剂类实体236个,疗法类实体999个。标注示例如图 2
所示。
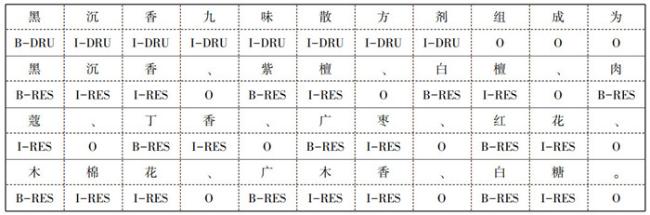
| 图 2 BIO序列标注示例 |
3.4 实验方法与参数设置
本文的实验平台为恒源云(GPUSHARE)云服务器Linux操作系统、2080ti(11G)GPU(显卡) 类型、16G运行内存、Python3.7.10编程语言、Tensorflow1.15.5深度学习框架。主要模型参数设置如下:字符向量长度为128,ALBERT隐藏层的大小为768,ALBERT学习率为2e-5。为了测试ALBERT-BiLSTM-CRF模型的性能,将标注语料按8 ∶ 2的比例划分为训练集和测试集,用于模型的训练与测试,并从训练集当中随机抽出20%作为验证集来评估模型效果。
3.5 评价指标
本文采用自然语言处理当中常用的精确度(Precision,P)、召回率(Recall,R)和F1-score作为度量指标,检验各个模型在命名实体识别中的效果[23],具体内容如下:
精确度是指被预测为正样本的正确率,公式为: Precision =TPTP+FP,其中TP代表模型运算中输出正确的正例,FP代表模型运算中输出错误的正例。
召回率代表实际为正样本被正确预测的比例,公式: Recall =TPTP+FN,其中FN代表的是模型中输出错误的反例。
F1-score为精确率和召回率两种指标的调和平均值,模型的综合抽取效果与F1-score数值正相关[23],公式为:F1− score =2∗ precision ∗ Recall Precision + Recall ,F1-score越大说明模型质量越高。
3.6 实验结果分析
为检验本文所提出的藏医古籍命名实体识别模型的性能,统一使用标注好的藏医语料数据集,对目前命名实体识别研究中常用的BERT-BiLSTM- CRF、BiLSTM-CRF、BERT模型进行训练和比较。4个模型的F1-score、Precision、Recall值如表 3
所示。
| 表 3 模型对比结果 |
| 模型 | F1-score(%) | Precision(%) | Recall(%) |
| ALBERT-BiLSTM-CRF | 96.28 | 96.12 | 96.44 |
| BERT-BiLSTM-CRF | 87.86 | 86.17 | 89.62 |
| BiLSTM-CRF | 89.65 | 90.79 | 88.54 |
| BERT | 88.06 | 85.06 | 91.27 |
由实验结果可知,4种深度学习模型在藏医古籍文献实体识别上存在一定的差异。其中达到最优效果的是ALBERT-BiLSTM-CRF模型,F1-score达到96.28%,说明该深度学习模型在藏医古籍文献这种小样本数据集命名实体识别中取得的效果较好,可以实现较优性能。此外还观察到,BERT模型与BiLSTM-CRF模型一起使用时,对F1-score没有提升作用,反而造成F1-score降低。而BiLSTM与CRF的结合使用,则会对F1-score和Precision值有一定的提升作用。
如图 3
所示,进一步分析ALBERT-BiLSTM-CRF、BERT-BiLSTM-CRF、BiLSTM-CRF、BERT 4种深度学习模型对不同实体类型的识别效果。以F1-score作为指标进行比较,由实验结果可见,药物(RES)类型的实体在各模型中识别效果最优。这是因为在《四部医典》中,对药物的描述较为集中,并且语义简单,识别效果较好。而疗法(THE)类型实体的识别结果在4种模型中的F1-score相对都比较低。在《四部医典》中,疗法数据较为复杂、分散,有的在介绍药物效果中出现,有的在疾病治疗方法中出现,疗法描述的不规则性导致模型在识别疗法时的难度增加,因此影响了模型训练的效果。在今后的研究工作中,还需要进一步扩大训练数据规模,标注更多语料来进行研究,从而改善和提高模型的识别效果。

| 图 3 各实体F1-score对比 |
4 藏医古籍命名实体的应用
运用机器学习与人工标注相结合的藏医古籍命名实体识别方法,可以在藏医古籍文本中识别出更多的藏医知识实体。本文进一步对实体之间的关系进行分析,构建了藏医古籍实体关系模型,如图 4
所示。
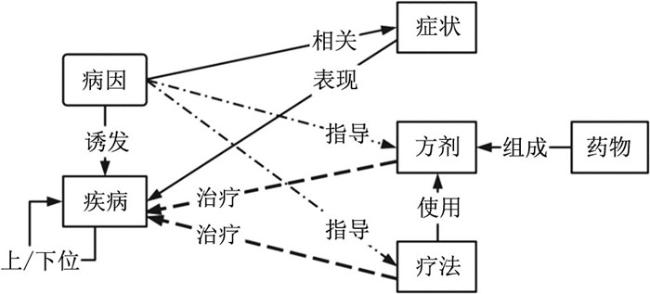
| 图 4 藏医古籍实体关系模型 |
以《中医药学语言系统语义网络框架》[24]作为标准,并借鉴其他中医语义网络模型,结合藏医文本自身的特点,对藏医实体间的关系进行规范化定义,如表 4
所示。
| 表 4 《四部医典》关系类型 |
| 序号 | 标签 | 关系类型 | 举例 |
| 1 | SUP/SUB | 上/下位关系 | 【(胃)病分胃热胃寒两大类,胃热又分传热混热降,毒攻霍乱再加胃败疽】这句话中胃病下分胃热和胃寒两种,胃热又下分为扩散症、紊乱症、胃毒症、胃疫疠、胃化脓等 |
| 2 | PAT | 诱发关系 | 【病因培根饮食沉且凉,病缘所依不惯又不适】所依、不习惯、不合适、本质是不消化等四种外因导致龙陪根病 |
| 3 | EFF | 治疗关系 | ①【功效药与病体当知之,第一斑蝥可引脉黄水】药物对病体的药效应该知道,第一斑蝥治疗排除黄水 ②【立止病痛械治用法良】热罨敷方法治疗止痛 |
| 4 | FOR | 组成关系 | 【沉香四味白糖骨汁送】这一汤剂主要由肉蔻、芸香、绿绒蒿组成,可以白糖骨汤冲好服用 |
| 5 | PER | 表现关系 | 【脾症痰类嘴唇结粘膜,寒冷昏暮胀而左肋疼】培根型脾病症状表现为嘴唇上结痰液,受寒或早上肠鸣,身体左侧剧痛等 |
| 6 | GUI | 指导关系 | 【(疫病)将肾麝香红花与砂仁,黄柏皮五灵脂向日葵】疫病由肾引发的可以用麝香、红花、砂仁、黄柏皮、五灵脂、向日葵来施治 |
| 7 | REL | 相关关系 | 【(天花)将于肝部目赤肝部痛,药加熊胆红花五灵脂】由肝引起的天花,与症状双目发红,肝部疼痛相关,可以用熊胆、红花、五灵脂来施治 |
| 8 | USE | 使用关系 | 【青蒿土碱酒曲煎汤浴,旧创肿与跛瘸得解除】青蒿、天然碱、酒糟配伍的药浴疗法,主治陈旧创伤、跛足 |
本文利用Neo4j图数据库建立《四部医典》知识库。Neo4j本质上是一种由节点(实体)和边(实体之间的关系)组成的关系图,可以用来揭示知识之间的关系[25]。将《四部医典》中识别出的实体存储于图数据库中,依据关系类型表对不同实体类型进行关系的识别和连接,实现藏医实体的关联,并进行可视化展示。图 5
是本文所构建的部分藏医古籍知识图谱。从该图可以看出,图中的节点向“龙”“赤巴”“培根”3个节点聚合,显示出“龙” “赤巴”“培根”作为藏医中的3个核心因素,在藏医病理与诊疗中的重要地位与作用。对照藏医古籍文献内容,“龙”“赤巴”“培根”构成了人的生命三要素,疾病也是由于这三要素失衡所致。由此可见,藏医古籍知识图谱能够反映出藏医古籍文献中的核心知识内容与知识关联。

| 图 5 《四部医典》部分知识图谱 |
是与疾病“热症扩散”相关的部分知识图谱。图谱清晰地显示出,“热症扩散”包括“心脏热疾扩散”“命脉热疾扩散”“肝脏热疾扩散”等类型的疾病,这类疾病由“赤巴”引起;由“赤巴”导致的疾病多呈现“口渴”“呕吐胆汁”“口苦”等症状,图谱中的“热疾扩散”类疾病也多呈现出这样的症状。通过观察各种方剂的药物构成可以发现,“红花”节点周围汇聚了多种方剂,可以初步判断“红花”是治疗各类“热症扩散”疾病的核心药物,可作为供藏医研究者进一步进行实验研究的依据。通过知识图谱还可以对比分析不同疾病的病因与症状表现,指导方剂与疗法的选择,辅助藏医工作者研究病机、病理,挖掘疾病用药的规律等。藏医古籍命名实体识别模型为藏医古籍知识的挖掘与知识图谱的构建提供了不可或缺的数据支持。
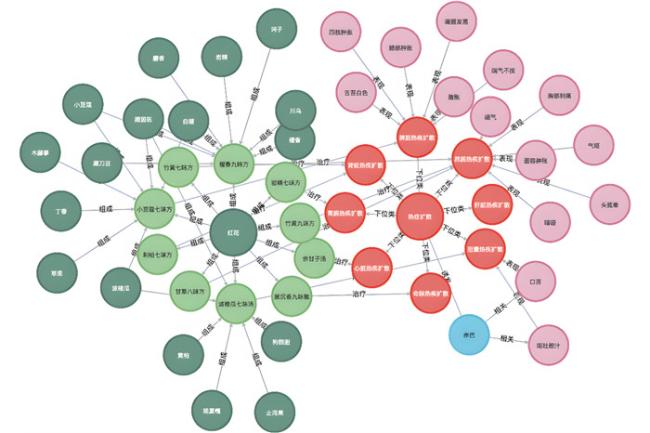
| 图 6 热症扩散知识图谱 |
5 结语
本文针对藏医古籍知识的特点,将人工标注与深度学习的方法相结合,构建了基于深度学习的命名实体识别模型。基于4种深度学习模型,选择具有“藏医百科全书”之称的、集藏医理论与实践知识于一体的藏医古籍《四部医典》进行实体识别实验,以确保所构建的命名实体识别模型具有通用有效性。结果表明,ALBERT-BiLSTM-CRF模型对藏医领域的实体识别效果最优。利用实体识别结果,构建了藏医古籍知识库与知识图谱,为藏医学的深入研究提供支持,也为藏医知识的进一步深度开发与利用提供了语料基础。
后续研究可以从以下几个方面展开:扩大语料规模,提升藏医实体识别模型的效果;进一步扩充、细化数据模型,以更全面地挖掘藏医古籍文献中的知识资源,支持藏医古籍知识的研究;在已有的数据集上进一步训练和优化模型,以提高模型在藏医古籍中命名实体识别任务中的性能;对藏医古籍命名实体识别系统进行功能模块的开发,使其能够被广泛应用于藏医潜在知识推理、医学自动问答、辅助决策等领域。
参考文献
| [1] | 新华社. 中共中央办公厅国务院办公厅印发《关于推进新时代古籍工作的意见》[J]. 中华人民共和国国务院公报, 2022,(12): 30- 33.https://www.cnki.com.cn/Article/CJFDTOTAL-GWYB202212005.htm本文引用 [1] |
| [2] | 全国古籍整理出版规划领导小组印发《2021—2035年国家古籍工作规划》[N]. 北京日报, 2022-10-12.本文引用 [1] |
| [3] | 龙从军, 安波. 中国少数民族语言文字信息处理的进展[J]. 暨南学报(哲学社会科学版), 2022, 44(9): 12- 23.https://www.cnki.com.cn/Article/CJFDTOTAL-JNXB202209002.htm |
| [4] | 才让南加, 仁增多杰, 多杰才让, 等. 数据挖掘技术在藏药方剂配伍规律研究中的应用思考[J]. 中国中药杂志, 2012, 37(16): 2366- 2367.https://www.cnki.com.cn/Article/CJFDTOTAL-ZGZY201216005.htm本文引用 [1] |
| [5] | 文成当智, 贡保东知, 东改措, 等. 《四部医典》用药规律——”味性化味”理论的科学内涵分析[J]. 中国实验方剂学杂志, 2019, 25(5): 201- 207.https://www.cnki.com.cn/Article/CJFDTOTAL-ZSFX201905030.htm本文引用 [1] |
| [6] | 娘本先. 基于知识元的藏医古籍本草知识表示研究[D]. 西宁: 青海民族大学, 2016.本文引用 [1] |
| [7] | 罗计根, 杜建强, 聂斌, 等. 基于双向LSTM和GBDT的中医文本关系抽取模型[J]. 计算机应用研究, 2019, 36(12): 3744- 3747.https://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ201912047.htm本文引用 [1] |
| [8] | Tao Q , Shan Q , Shen X Q , et al. KeMRE: Knowledge-enhanced Medical Relation Extraction for Chinese Medicine Instructions[J]. Journal of biomedical informatics, 2021, 120, 103834.https://doi.org/10.1016/j.jbi.2021.103834本文引用 [1] |
| [9] | Chen T , Wu M F , Li H X . A General Approach for Improving Deep Learning-based Medical Relation Extraction Using a Pre-trained Model and Fine-tuning[J]. Database: The Journal of Biological Databases and Curation, 2019, 2019(1): 116.本文引用 [1] |
| [10] | 肖瑞, 胡冯菊, 裴卫. 基于BiLSTM-CRF的中医文本命名实体识别[J]. 世界科学技术-中医药现代化, 2020, 22(7): 2504- 2510.https://www.cnki.com.cn/Article/CJFDTOTAL-SJKX202007047.htm本文引用 [1] |
| [11] | 谢靖, 刘江峰, 王东波. 古代中国医学文献的命名实体识别研究——以Flat-lattice增强的SikuBERT预训练模型为例[J]. 图书馆论坛, 2022, 42(10): 51- 60.https://www.cnki.com.cn/Article/CJFDTOTAL-TSGL202210008.htm本文引用 [1] |
| [12] | 何家欢, 刘勇国, 蒋羽, 等. 藏药药理命名实体识别[J]. 医学信息学杂志, 2020, 41(4): 30- 36.https://www.cnki.com.cn/Article/CJFDTOTAL-YXQB202004010.htm本文引用 [1] |
| [13] | 宇妥· 元丹贡布, 等. 四部医典[M]. 马世林, 等译注. 上海: 上海科学技术出版社, 1987.本文引用 [1] |
| [14] | 刘浏, 王东波. 命名实体识别研究综述[J]. 情报学报, 2018, 37(3): 329- 340.https://www.cnki.com.cn/Article/CJFDTOTAL-QBXB201803010.htm本文引用 [1] |
| [15] | 毛继组. 藏医基础理论[M]. 兰州: 甘肃民族出版社, 1999.本文引用 [1] |
| [16] | 史加荣, 马媛媛. 深度学习的研究进展与发展[J]. 计算机工程与应用, 2018, 54(10): 1- 10.https://www.cnki.com.cn/Article/CJFDTOTAL-JSGG201810001.htm |
| [17] | 何炎祥, 罗楚威, 胡彬尧. 基于CRF和规则相结合的地理命名实体识别方法[J]. 计算机应用与软件, 2015, 32(1): 179-185, 202.https://www.cnki.com.cn/Article/CJFDTOTAL-JYRJ201501047.htm本文引用 [1] |
| [18] | Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv Preprint arXiv: 1810.04805, 2018. |
| [19] | Lan Z, Chen M, Goodman S, et al. Albert: A Lite Bert for Self-supervised Learning of Language Representations[J]. arXiv Preprint arXiv: 1909.11942, 2019.本文引用 [1] |
| [20] | 黄忠祥, 李明. BiGRU结合注意力机制的文本分类研究[J]. 北京联合大学学报, 2021, 35(3): 47- 52.https://www.cnki.com.cn/Article/CJFDTOTAL-BJLH202103011.htm本文引用 [1] |
| [21] | 孙晓聪, 付玉慧. 基于RF-双向LSTM的集装箱吞吐量预测[J]. 上海海事大学学报, 2022, 43(1): 60- 65.https://www.cnki.com.cn/Article/CJFDTOTAL-SHHY202201009.htm本文引用 [1] |
| [22] | 余陆峰. 基于深度学习的客家方言语音识别[D]. 广州: 华南理工大学, 2019.本文引用 [1] |
| [23] | 彭博. 基于ALBERT的网络文物信息资源实体关系抽取方法研究[J]. 情报杂志, 2022, 41(8): 156-162, 178.https://www.cnki.com.cn/Article/CJFDTOTAL-QBZZ202208021.htm本文引用 [2] |
| [24] | GB/T 38324-2019. 健康信息学中医药学语言系统语义网络框架[S]. 中华人民共和国国家市场监督管理总局; 中国国家标准化管理委员会, 2019-12-10.本文引用 [1] |
| [25] | 赵雪芹, 李天娥, 曾刚. 基于Neo4j的万里茶道数字资源知识图谱构建研究[J]. 情报资料工作, 2022, 43(5): 89- 97.https://www.cnki.com.cn/Article/CJFDTOTAL-QBZL202205011.htm本文引用 [1] |
基金
教育部人文社会科学研究规划基金项目“基于数据生态的图书馆知识服务价值共创的演化机制、模拟实验及优化研究”(19YJA870007)
版权
版权所有,未经授权不得转载或用于任何商业用途。
 PDF(2293 KB)
PDF(2293 KB)
247
Accesses
0
Citation

段落导航
相关文章
- 摘要
- Abstract
- 关键词
- Key words
- 引用本文
- 1 研究现状
- 1.1 传统的藏医文献研究方法
- 1.2 基于机器学习的传统医学文献命名实体识别方法
- 2 关键技术与藏医古籍命名实体识别模型构建
- 2.1 关键技术
- 2.1.1 ALBERT模型
- 2.1.2 BiLSTM模型
- 2.1.3 CRF模型
- 2.2 藏医古籍命名实体识别模型构建
 图 1 ALBERT-BiLSTM-CRF模型
图 1 ALBERT-BiLSTM-CRF模型- 3 实验与结果分析
- 3.1 数据来源
- 3.2 实体类型
 表 1 《四部医典》实体类型
表 1 《四部医典》实体类型- 3.3 数据标注
- 表 2 人工标注示例
- 图 2 BIO序列标注示例
- 3.4 实验方法与参数设置
- 3.5 评价指标
- 3.6 实验结果分析
- 表 3 模型对比结果
- 图 3 各实体F1-score对比
- 4 藏医古籍命名实体的应用
- 图 4 藏医古籍实体关系模型
- 表 4 《四部医典》关系类型
- 图 5 《四部医典》部分知识图谱
- 图 6 热症扩散知识图谱
- 5 结语
- 参考文献
- 基金
- 版权
地址:长春市经济技术开发区深圳街940号 邮编:130033 电话:0431-85647990 E-mail:xdqb257@vip.163.com
网站版权所有 © 2022 《现代情报》编辑部
本系统由北京玛格泰克科技发展有限公司设计开发 技术支持:support@magtech.com.cn
知识共享许可协议




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}